What should we include in the Global Open Data Index? From reference data to civil society audit.

Three years ago we decided to begin to systematically track the state of open data around the world. We wanted to know which countries were the strongest and which national governments were lagging behind in releasing the key datasets as open data so that we could better understand the gaps and work with our global community to advocate for these to be addressed.
In order to do this, we created the Global Open Data Index, which was a global civil society collaboration to map the state of open data in countries around the world. The result was more than just a benchmark. Governments started to use the Index as a reference to inform their priorities on open data. Civil society actors began to use it as a tool to teach newcomers about open data and as advocacy mechanism to encourage governments to improve their performance in releasing key datasets.
Three years on we want the Global Open Data Index to become much more than a measurement tool. We would like it to become a civil society audit of the data revolution. As a tool driven by campaigners, researchers and advocacy organisations, it can help us, as a movement, determine the topics and issues we want to promote and to track progress on them together. This will mean going beyond a “baseline” of reference datasets which are widely held to be important. We would like the Index to include more datasets which are critical for democratic accountability but which may be more ambitious than what is made available by many governments today.
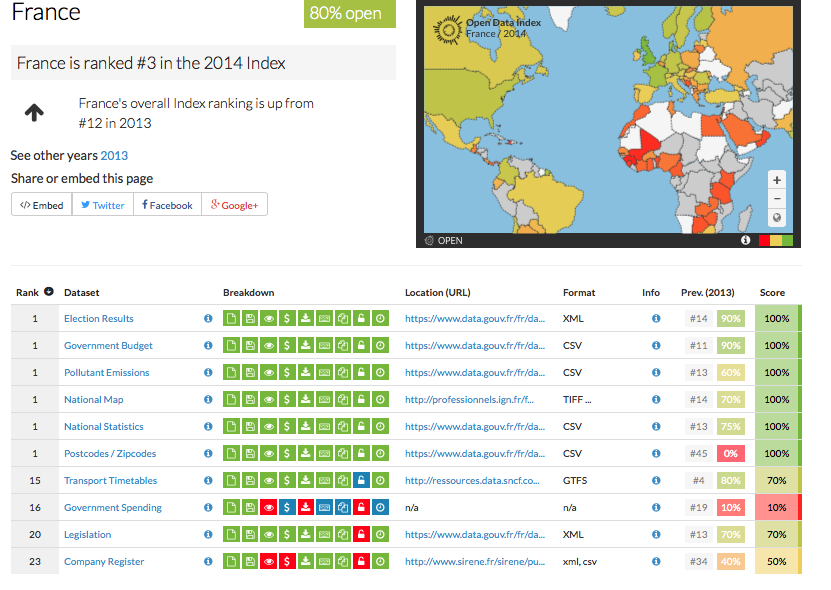
The 10 datasets we have now and their score in France
To do this, we are today opening a consultation on what themes and datasets civil society think should be included in the Global Open Data Index. We want you to help us decide on the priority datasets that we should be tracking and advocating to have opened up. We want to work with our global network to collaboratively determine the datasets that are most important to obtaining progress on different issues – from democratic accountability, to stronger action on climate change, to tackling tax avoidance and tax evasion.
Drawing inspiration from our chapter Open Knowledge Belgium’s activities to run their own local open data census, we decided to conduct a public consultation. This public consultation will be divided into two parts:
Crowdsourced Survey – Using the platform of WikiSurvey, a platform inspired by kittens war (and as we all know, anything inspired by viral kittens cannot be bad), we are interested in what you think about which datasets are most important. The platform is simple, just choose between two datasets the one that you see as being a higher priority to include in the Global Open Data Index. Can’t find a dataset that you think is important? Add your own idea to the pool. You do not have a vote limit, so vote as much as you want and shape the index. SUBMIT YOUR DATA NOW
Our Wiki Survey
Focused consultation with civil society organisations – This survey will be sent to a group of NGOs working on a variety of issues to find out what they think about what specific datasets are needed and how they can be used. We will add ideas from the survey to general pool as they come in. Want to answer the survey as well? You can find it here.
This public consultation will be open for the next 10 days and will be closed at June 28th. At the end of the process we will analyse the results and share them with you.
We hope that this new process that we are starting today will lead to an even better index. If you have thoughts about the process, please do share your thoughts with us on our new forum on this topic: https://discuss.okfn.org/c/open-data-index