Visualizing Bikeshare Data
Seattle’s Pronto bikeshare system recently announced a Data Challenge for data visualization using their first year of trip data. As avid cyclists and data analysis junkies, we of course took the bait. Below is a brief description of our Pronto Databrowser submission.
At Mazama Science we focus on creating interactive websites that allow people to thoroughly interrogate interesting datasets. Each project begins with a thorough investigation of the original data to figure out what stories can be told. This is then followed by an exploration of data visualization styles that help communicate the stories we have found. Finally, a user interface is developed that guides people to subset the data in ways that lead to interesting stories. Guiding people to achieve their own “Aha!” experiences is the best way to motivate data based decision making.
Pronto Data
The Pronto Data Challenge data consists of four datasets: trip data, station metadata, daily weather data and minute-to-minute station status (#docks empty/full/broken).
The raw csv files have the following sizes:
8.0K 2015_station_data.csv 830M 2015_status_data.csv 21M 2015_trip_data.csv 28K 2015_weather_data.csv
For any investigation of human behavior, the most interesting dataset is the trip data which contains 142,846 trip records with the following variables:
- trip_id
- starttime
- stoptime
- bikeid
- tripduration
- from_station_name
- to_station_name
- from_station_id
- to_station_id
- usertype
- gender
- birthyear
To generate maps, this must be combined with station metadata which has:
- id
- name
- terminal
- lat
- long
- dockcount
- online
We can amend the station metadata by adding station elevations using the Google Maps Elevation API. Using as-the-crow-flies distances from R’s geosphere package, we can also add station-to-station distances to the station metadata and, through lookup, to the trip data.
Now we have a couple of rich datasets to play with.
Data Visualization
After playing around with our amended datasets, we realized that, even though Pronto bikeshare usage is very seasonal, it isn’t that affected by weather. There aren’t really any muggy days in Seattle as temperature and humidity are inversely correlated. And it can be cool and wet any time of the year. (Though 2015 had unusually long stretches of nice weather.) Subsetting the trip data by gender and age also doesn’t lead to anything particularly revealing.
The most interesting stories we found have to do with the variations in usage patterns between annual members and short-term pass holders; with time-of-day and day-of-week; and depending on the departure station.
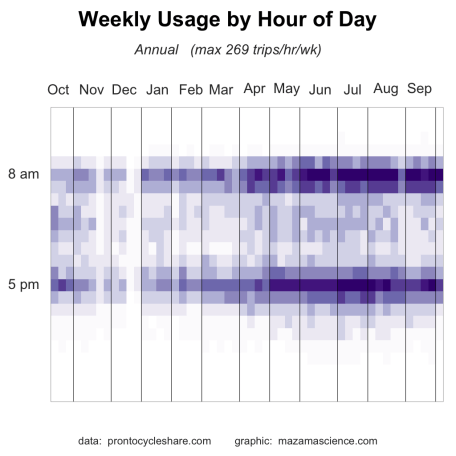
You can explore the data yourself with a variety of visualizations at our Pronto Databrowser. Here are two plots from the Data Stories page that tell pretty good stories by themselves:
The time-of-day usage plot shows that: 1) annual pass holders use the bikes during the morning and evening commute; and 2) usage is heaviest in the summer.

The elevation plot shows that annual pass holders vastly prefer coasting to humping up Seattle’s steep hills.

We invite you to find and tell your own stories by poking around and exploring this very interesting dataset.
Happy Exploring!
R-bloggers.com offers daily e-mail updates about R news and tutorials on topics such as: visualization (ggplot2, Boxplots, maps, animation), programming (RStudio, Sweave, LaTeX, SQL, Eclipse, git, hadoop, Web Scraping) statistics (regression, PCA, time series, trading) and more…